Background: Machine Learning
Given that a number of users of the ML-Agents Toolkit might not have a formal machine learning background, this page provides an overview to facilitate the understanding of the ML-Agents Toolkit. However, we will not attempt to provide a thorough treatment of machine learning as there are fantastic resources online.
Machine learning, a branch of artificial intelligence, focuses on learning patterns from data. The three main classes of machine learning algorithms include: unsupervised learning, supervised learning and reinforcement learning. Each class of algorithm learns from a different type of data. The following paragraphs provide an overview for each of these classes of machine learning, as well as introductory examples.
Unsupervised Learning
The goal of unsupervised learning is to group or cluster similar items in a data set. For example, consider the players of a game. We may want to group the players depending on how engaged they are with the game. This would enable us to target different groups (e.g. for highly-engaged players we might invite them to be beta testers for new features, while for unengaged players we might email them helpful tutorials). Say that we wish to split our players into two groups. We would first define basic attributes of the players, such as the number of hours played, total money spent on in-app purchases and number of levels completed. We can then feed this data set (three attributes for every player) to an unsupervised learning algorithm where we specify the number of groups to be two. The algorithm would then split the data set of players into two groups where the players within each group would be similar to each other. Given the attributes we used to describe each player, in this case, the output would be a split of all the players into two groups, where one group would semantically represent the engaged players and the second group would semantically represent the unengaged players.
With unsupervised learning, we did not provide specific examples of which players are considered engaged and which are considered unengaged. We just defined the appropriate attributes and relied on the algorithm to uncover the two groups on its own. This type of data set is typically called an unlabeled data set as it is lacking these direct labels. Consequently, unsupervised learning can be helpful in situations where these labels can be expensive or hard to produce. In the next paragraph, we overview supervised learning algorithms which accept input labels in addition to attributes.
Supervised Learning
In supervised learning, we do not want to just group similar items but directly learn a mapping from each item to the group (or class) that it belongs to. Returning to our earlier example of clustering players, let's say we now wish to predict which of our players are about to churn (that is stop playing the game for the next 30 days). We can look into our historical records and create a data set that contains attributes of our players in addition to a label indicating whether they have churned or not. Note that the player attributes we use for this churn prediction task may be different from the ones we used for our earlier clustering task. We can then feed this data set (attributes and label for each player) into a supervised learning algorithm which would learn a mapping from the player attributes to a label indicating whether that player will churn or not. The intuition is that the supervised learning algorithm will learn which values of these attributes typically correspond to players who have churned and not churned (for example, it may learn that players who spend very little and play for very short periods will most likely churn). Now given this learned model, we can provide it the attributes of a new player (one that recently started playing the game) and it would output a predicted label for that player. This prediction is the algorithms expectation of whether the player will churn or not. We can now use these predictions to target the players who are expected to churn and entice them to continue playing the game.
As you may have noticed, for both supervised and unsupervised learning, there are two tasks that need to be performed: attribute selection and model selection. Attribute selection (also called feature selection) pertains to selecting how we wish to represent the entity of interest, in this case, the player. Model selection, on the other hand, pertains to selecting the algorithm (and its parameters) that perform the task well. Both of these tasks are active areas of machine learning research and, in practice, require several iterations to achieve good performance.
We now switch to reinforcement learning, the third class of machine learning algorithms, and arguably the one most relevant for the ML-Agents Toolkit.
Reinforcement Learning
Reinforcement learning can be viewed as a form of learning for sequential decision making that is commonly associated with controlling robots (but is, in fact, much more general). Consider an autonomous firefighting robot that is tasked with navigating into an area, finding the fire and neutralizing it. At any given moment, the robot perceives the environment through its sensors (e.g. camera, heat, touch), processes this information and produces an action (e.g. move to the left, rotate the water hose, turn on the water). In other words, it is continuously making decisions about how to interact in this environment given its view of the world (i.e. sensors input) and objective (i.e. neutralizing the fire). Teaching a robot to be a successful firefighting machine is precisely what reinforcement learning is designed to do.
More specifically, the goal of reinforcement learning is to learn a policy, which is essentially a mapping from observations to actions. An observation is what the robot can measure from its environment (in this case, all its sensory inputs) and an action, in its most raw form, is a change to the configuration of the robot (e.g. position of its base, position of its water hose and whether the hose is on or off).
The last remaining piece of the reinforcement learning task is the reward signal. The robot is trained to learn a policy that maximizes its overall rewards. When training a robot to be a mean firefighting machine, we provide it with rewards (positive and negative) indicating how well it is doing on completing the task. Note that the robot does not know how to put out fires before it is trained. It learns the objective because it receives a large positive reward when it puts out the fire and a small negative reward for every passing second. The fact that rewards are sparse (i.e. may not be provided at every step, but only when a robot arrives at a success or failure situation), is a defining characteristic of reinforcement learning and precisely why learning good policies can be difficult (and/or time-consuming) for complex environments.
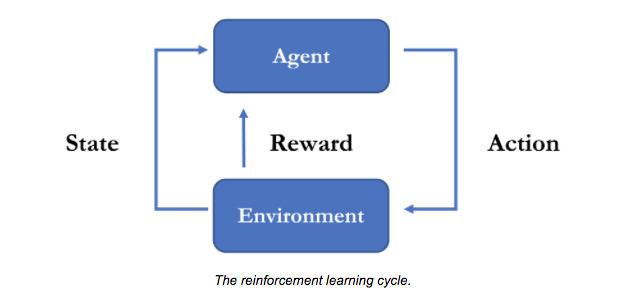
Learning a policy usually requires many trials and iterative policy updates. More specifically, the robot is placed in several fire situations and over time learns an optimal policy which allows it to put out fires more effectively. Obviously, we cannot expect to train a robot repeatedly in the real world, particularly when fires are involved. This is precisely why the use of Unity as a simulator serves as the perfect training grounds for learning such behaviors. While our discussion of reinforcement learning has centered around robots, there are strong parallels between robots and characters in a game. In fact, in many ways, one can view a non-playable character (NPC) as a virtual robot, with its own observations about the environment, its own set of actions and a specific objective. Thus it is natural to explore how we can train behaviors within Unity using reinforcement learning. This is precisely what the ML-Agents Toolkit offers. The video linked below includes a reinforcement learning demo showcasing training character behaviors using the ML-Agents Toolkit.

Similar to both unsupervised and supervised learning, reinforcement learning also involves two tasks: attribute selection and model selection. Attribute selection is defining the set of observations for the robot that best help it complete its objective, while model selection is defining the form of the policy (mapping from observations to actions) and its parameters. In practice, training behaviors is an iterative process that may require changing the attribute and model choices.
Training and Inference
One common aspect of all three branches of machine learning is that they all involve a training phase and an inference phase. While the details of the training and inference phases are different for each of the three, at a high-level, the training phase involves building a model using the provided data, while the inference phase involves applying this model to new, previously unseen, data. More specifically:
- For our unsupervised learning example, the training phase learns the optimal two clusters based on the data describing existing players, while the inference phase assigns a new player to one of these two clusters.
- For our supervised learning example, the training phase learns the mapping from player attributes to player label (whether they churned or not), and the inference phase predicts whether a new player will churn or not based on that learned mapping.
- For our reinforcement learning example, the training phase learns the optimal policy through guided trials, and in the inference phase, the agent observes and takes actions in the wild using its learned policy.
To briefly summarize: all three classes of algorithms involve training and inference phases in addition to attribute and model selections. What ultimately separates them is the type of data available to learn from. In unsupervised learning our data set was a collection of attributes, in supervised learning our data set was a collection of attribute-label pairs, and, lastly, in reinforcement learning our data set was a collection of observation-action-reward tuples.
Deep Learning
Deep learning is a family of algorithms that can be used to address any of the problems introduced above. More specifically, they can be used to solve both attribute and model selection tasks. Deep learning has gained popularity in recent years due to its outstanding performance on several challenging machine learning tasks. One example is AlphaGo, a computer Go program, that leverages deep learning, that was able to beat Lee Sedol (a Go world champion).
A key characteristic of deep learning algorithms is their ability to learn very complex functions from large amounts of training data. This makes them a natural choice for reinforcement learning tasks when a large amount of data can be generated, say through the use of a simulator or engine such as Unity. By generating hundreds of thousands of simulations of the environment within Unity, we can learn policies for very complex environments (a complex environment is one where the number of observations an agent perceives and the number of actions they can take are large). Many of the algorithms we provide in ML-Agents use some form of deep learning, built on top of the open-source library, PyTorch.