![]()
![]()
![]()
![]()
📣 PSP-HDRI+ accepted at ICML 2022
❇️ PSP-HDRI+: A Synthetic Dataset Generator for Pre-Training of Human-Centric Computer Vision Models
PSP-HDRI+ Paper Poster PSP-HDRI+ Demo Video

Salehe Erfanian Ebadi,
Saurav Dhakad,
Sanjay Vishwakarma,
Chunpu Wang,
You-Cyuan Jhang,
Maciek Chociej,
Adam Crespi,
Alex Thaman,
Sujoy Ganguly
Unity Technologies
Citation
@inproceedings{ebadi2022psphdri,
title={PSP-HDRI+: A Synthetic Dataset Generator for Pre-Training of Human-Centric Computer Vision Models},
author={Erfanian Ebadi, Salehe and Dhakad, Saurav and Vishwakarma, Sanjay and Wang, Chunpu and Jhang, You-Cyuan and
Chociej, Maciek and Crespi, Adam and Thaman, Alex and Ganguly, Sujoy},
booktitle={First Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward at ICML 2022},
year={2022},
}
❇️ PeopleSansPeople v1.0
Paper macOS and Linux Binaries Demo Video

Salehe Erfanian Ebadi,
You-Cyuan Jhang,
Alex Zook,
Saurav Dhakad,
Adam Crespi,
Pete Parisi,
Steve Borkman,
Jonathan Hogins,
Sujoy Ganguly
Unity Technologies
Summary
- We introduce PeopleSansPeople, a human-centric privacy-preserving synthetic data generator with highly parametrized domain randomization.
- PeopleSansPeople contains simulation-ready 3D human assets, a parameterized lighting and camera system, and generates 2D and 3D bounding box, instance and semantic segmentation, and COCO pose labels.
- We use naïve ranges for the domain randomization and generate a synthetic dataset with labels.
- We provide some guarantees and analysis of human activities, poses, and context diversity on our synthetic data.
- We found that pre-training a network using synthetic data and fine-tuning on target real-world data (COCO-person train) resulted in few-shot transfer keypoint AP of 60.37 ± 0.48 (COCO test-dev2017) outperforming models trained with the same real data alone (keypoint AP of 55.80) and pre-trained with ImageNet (keypoint AP of 57.50).
Abstract (click to expand)
In recent years, person detection and human pose estimation have made great strides, helped by large-scale labeled datasets. However, these datasets had no guarantees or analysis of human activities, poses, or context diversity. Additionally, privacy, legal, safety, and ethical concerns may limit the ability to collect more human data. An emerging alternative to real-world data that alleviates some of these issues is synthetic data. However, creation of synthetic data generators is incredibly challenging and prevents researchers from exploring their usefulness. Therefore, we release a human-centric synthetic data generator PeopleSansPeople which contains simulation-ready 3D human assets, a parameterized lighting and camera system, and generates 2D and 3D bounding box, instance and semantic segmentation, and COCO pose labels. Using PeopleSansPeople, we performed benchmark synthetic data training using a Detectron2 Keypont R-CNN variant. We found that pre-training a network using synthetic data and fine-tuning on target real-world data (few-shot transfer to limited subsets of COCO-person train) resulted in a keypoint AP of 60.37 ± 0.48 (COCO test-dev2017) outperforming models trained with the same real data alone (keypoint AP of 55.80) and pre-trained with ImageNet (keypoint AP of 57.50). This freely-available data generator should enable a wide range of research into the emerging field of simulation to real transfer learning in the critical area of human-centric computer vision.Synthetic Data Generator
PeopleSansPeople executable binaries come with:
- 28 parameterized simulation-ready 3D human assets
- 39 diverse animation clips
- 21,952 unique clothing textures (from 28 albedos, 28 masks, and 28 normals)
- rameterized lighting
- Parameterized camera system
- Natural backgrounds
- Primitive occluders/distractors
A comparison between our benchmark generated data with PeopleSansPeople and the COCO person dataset.
| #train | #validation | #instances (train) | #instances w/ kpts (train) | |
|---|---|---|---|---|
| COCO | 64,115 | 2,693 | 262,465 | 149,813 |
| PeopleSansPeople | 490,000 | 10,000 | >3,070,000 | >2,900,000 |
Generated Data and Labels
PeopleSansPeople produces the following types of labels in COCO format: 2D bounding box, human keypoints, semantic and instance segmentation masks. In addition PeopleSansPeople generates 3D bounding boxes which are provided in Unity’s Perception format.

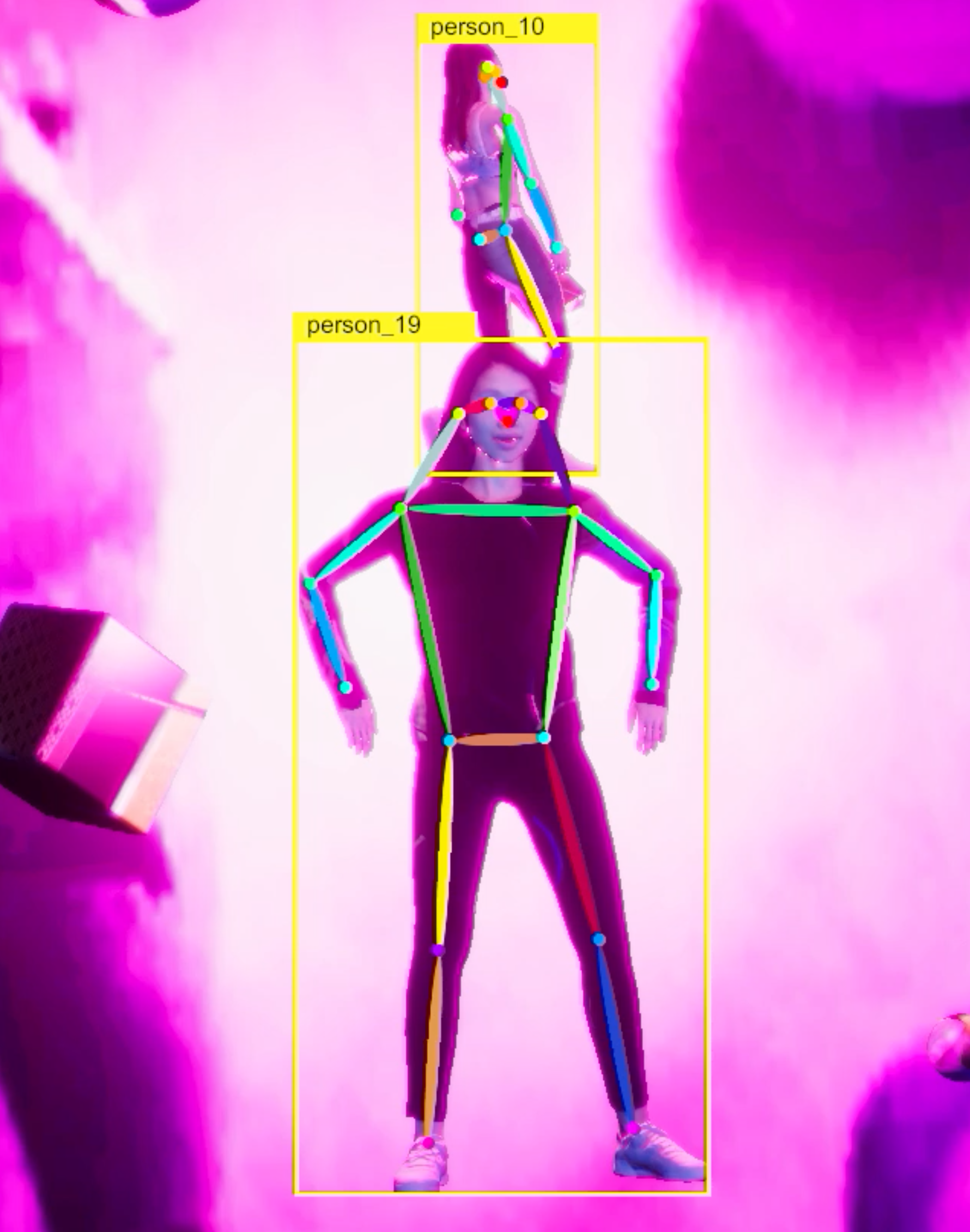


Generated image and corresponding labels: 2D bounding box, human keypoints, semantic and instance segmentation masks in COCO format.
3D bounding box annotations are provided separately in Unity Perception format.
Benchmark Results
Here we show a comparison of gains obtained from pre-training on our synthetic data and fune-tuning on COCO person class over training from scratch and pre-training with ImageNet. For each dataset size we show the results of the best performing model.
| bbox AP (COCO person val2017) | |||||
|---|---|---|---|---|---|
| size of real data | scratch | w/ ImageNet | w/ PeopleSansPeople | Δ / scratch | Δ / ImageNet |
| 641 | 13.82 | 27.61 | 42.58 | +28.76 | +14.97 |
| 6411 | 37.82 | 42.53 | 49.04 | +11.22 | +6.51 |
| 32057 | 52.15 | 52.75 | 55.04 | +2.89 | +2.29 |
| 64115 | 56.73 | 56.09 | 57.44 | +0.71 | +1.35 |
| keypoint AP (COCO person val2017) | |||||
|---|---|---|---|---|---|
| size of real data | scratch | w/ ImageNet | w/ PeopleSansPeople | Δ / scratch | Δ / ImageNet |
| 641 | 7.47 | 23.51 | 46.40 | +38.93 | +22.89 |
| 6411 | 39.48 | 45.99 | 55.21 | +15.73 | +9.22 |
| 32057 | 58.68 | 60.28 | 63.38 | +4.70 | +3.10 |
| 64115 | 65.12 | 65.10 | 66.83 | +1.71 | +1.73 |
| keypoint AP (COCO test-dev2017) | |||||
|---|---|---|---|---|---|
| size of real data | scratch | w/ ImageNet | w/ PeopleSansPeople | Δ / scratch | Δ / ImageNet |
| 641 | 6.40 | 21.90 | 44.43 | +38.03 | +22.53 |
| 6411 | 37.30 | 44.20 | 52.70 | +15.40 | +8.50 |
| 32057 | 55.80 | 57.50 | 60.37 | +4.57 | +2.87 |
| 64115 | 62.00 | 62.40 | 63.47 | +1.47 | +1.07 |
Simulated Clothing Appearance Diversity


Top row: our 3D human assets from RenderPeople with their original clothing textures.
Bottom row: using our Shader Graph randomizers we are able to swap out clothing texture albedos, masks, and normals,
yielding very diverse-looking textures on the clothing, without needing to swap out the clothing items themselves.
Additional examples
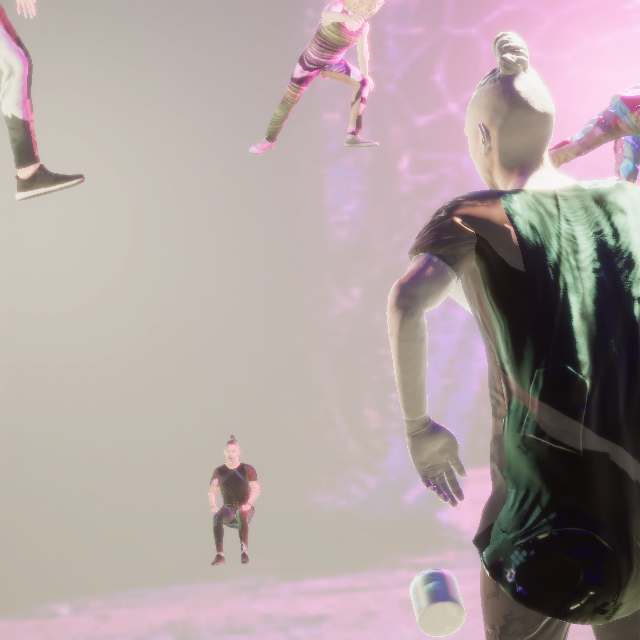
















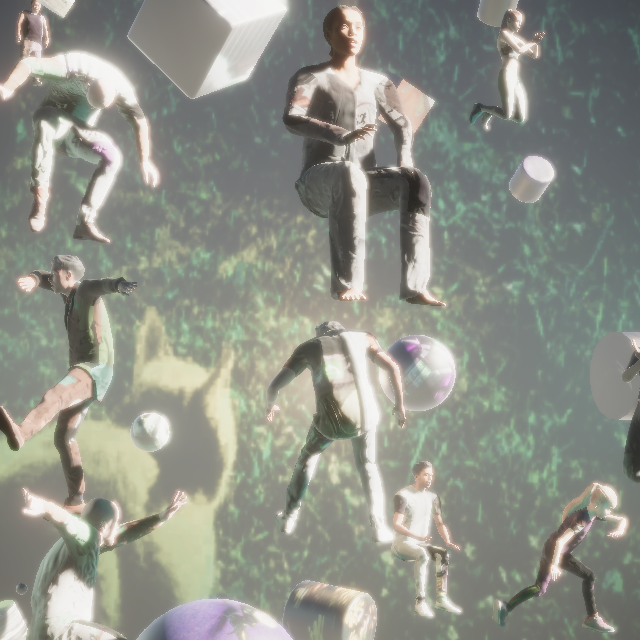

















Additional images generated with PeopleSansPeople.
Notice the high diversity of lighting, camera perspectives, scene background and occluders, as well as human poses,
their proximity to each other and the camera, and the clothing texture variations. Our domain randomization is done
here with naïvely-chosen ranges with uniform distributions. It is possible to drastically change the look and the
structure of the scenes by varying the randomizer parameters.
Citation
@article{ebadi2021peoplesanspeople,
title={PeopleSansPeople: A Synthetic Data Generator for Human-Centric Computer Vision},
author={Erfanian Ebadi, Salehe and Jhang, You-Cyuan and Zook, Alex and Dhakad, Saurav and
Crespi, Adam and Parisi, Pete and Borkman, Steve and Hogins, Jonathan and Ganguly, Sujoy},
year={2021},
eprint={2112.09290},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Source code
Unity Environment Template here
macOS and Linux binaries here
Related links
- Watch Unity’s webinar on Using Synthetic Data for Computer Vision Model Training Session 1 on YouTube
- Watch Unity’s webinar on Using Synthetic Data for Computer Vision Model Training Session 2 on YouTube
- Watch our Keynote in ICCV 2021 Fifth Workshop on Computer Vision for AR/VR (CV4ARVR)
- Watch our Keynote at AI @ Scale 2022
- Check out HumanDataset: World’s most popular 3D human datasets to create ground truth synthtic data for computer vision research and simulation
- Unity’s Blog Post on Human-Centric Computer Vision with Unity Synthetic Data
- Unity’s Perception Package
- Unity Computer Vision
- Unity’s Perception Tutorial
- Unity’s Human Pose Labeling and Randomization Tutorial
- Drone Pose Estimation and Navigation with Unity Project
- SynthDet Project
- Robotics Object Pose Estimation Demo
PeopleSansPeople in the press
- VentureBeat: How the metaverse will let you simulate everything
- WIRED: Gaming Giant Unity Wants to Digitally Clone the World
License
PeopleSansPeople is licensed under the Apache License, Version 2.0. See LICENSE for the full license text.